
Comparing RNA fusion detection tools with simulated long reads
Introduction
Genomic instability is a central characteristic of cancer and gene mutation, translocation, insertion, and deletion events are commonly observed in tumor cells. Fusion genes are oncogenes that have been discovered throughout the past few decades that are advantageous to the diagnosis of cancer, as they are only expressed in tumor cells. Gene fusions play a major role in tumorigenesis and are expected to be responsible for 20% of cancer morbidities. Hematologic malignancies commonly contain fusion genes such as BCR-ABL a fusion that occurs in 95% of chronic myeloid leukemia patients and PML-RARA a fusion gene-occurring in 95% of acute promyelocytic cancers. Three types of gene fusions are found in 50-70% of prostate cancers. These three fusions involve the fusion of the androgen-regulated promoter for transmembrane protease gene (TMPRSS2) to ETS transcription factor genes ERG, ETV1, and ETV4. In colorectal cancer, a disease where 75-95% of patients do not have a genetic predisposition to the disease, there is a roughly 10% chance of the RSP03-PTPRK gene fusion being present. A study by the Gao group predicted 25,664 fusion genes from 9,624 sample in the Cancer Genome Atlas (Gao et. al, 2018). Various therapeutics have been made and are in development to target these genes.
The emergence of next-generation high-throughput sequencing technology and related tools have made identifying fusions genes from transcriptomic data a common task in cancer research. Second generation technologies which produce short, accurate reads already have dozens of tools for detecting fusions genes from RNA-seq data (Uhrig, et. al, 2021). Two broad approaches to identifying fusions genes from RNAseq data characterize the majority of tools. The “mapping first” approaches align RNAseq reads to a reference genome before identifying discordantly mapped reads that suggest chromosome rearrangements and assembly-first approaches that involves assembly of reads into long transcripts before imbuing chimeric transcript from those assemblies that suggest fusions. The number of reads split reads that are contained within these rearrangements are used as evidence to support the case for a fusion gene (Hass, et. al. 2019). A recent study of short read RNAseq fusion detection tools has identified STAR-fusion and Arriba as excellent tools for fusion detection that outperform others tested. Both these methods begin by using the STAR aligner to align the transcriptome and use a “mapping first” approach to detecting fusion genes (Creason, et. al. 2021).
Short read RNAseq does falter in some areas when it comes to identifying bona fide fusion genes. Short reads give a rather poor signal of splicing events that cause split mapping of reads near fusion breakpoints, making them less able to detect gene isoforms. Additionally, library preparation approaches that may lead to artificial chimeric reads that are difficult to differentiate from actual genomic transcriptional events without the addition of genomic sequencing data. Third-generation sequencing technologies, namely long read transcriptome sequencing technology is a relatively recent tool that promises large-part or even full-length single reads of transcripts, which can capture the entirety of a transcript isoform without the need for transcriptome assembly.
In this post, we compare four software tools used to detect fusion genes from long read transcriptome sequencing data: LongGF, JAFFAL, Genion, and Aeron. We have generated simulated transcriptome data with simulated fusions transcripts to assess the performance of these tools. In addition, we will be assessing their performance against a short read RNA-seq fusion gene detection tool, Arriba.
LongGF
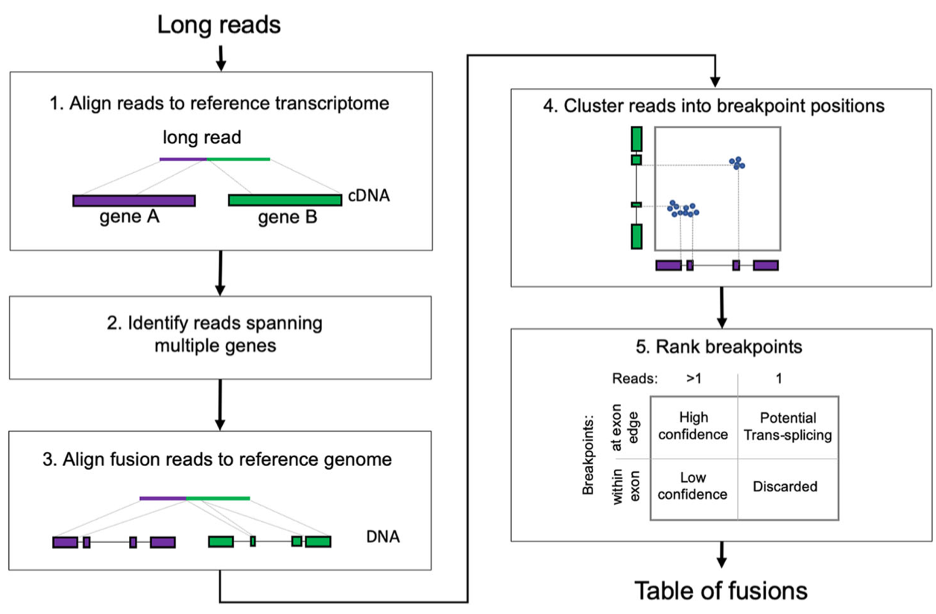
LongGF is a long read fusion transcript detection tool that utilizes a “mapping first” approach. A pipeline begins by aligning long-reads using an alignment tool such as minimap2. It considers reads that have alignments in two genomic positions (a primary and supplementary read). If it is determined that a size and overlap of mapped positions and GTF-defined exons are significant. Various filtering steps are taken: First, reads that span pseudogenes and genes that have significant overlap are excluded. Second, reads whose alignment do not have an appropriately sized gap are excluded. (Image from Liu et. al. 2020)

JAFFAL
JAFFAL is a fusion transcript detection pipeline built off JAFFA’s Direct protocol, which is itself a short read fusion detection tool. The first step in this pipeline is to align long reads to a reference transcriptome using minimap2 to obtain candidate fusion transcripts that map to two genes and then to perform a second alignment to a reference genome to these selected reads. This is meant to reduce false positive rates and reduce the runtime as the computationally more expensive step of aligning non-candidate reads to the refence genome is avoided. JAFFAL next uses end genome position alignments to determine fusions breakpoints. JAFFAL aligns transcript breakpoints to exon boundaries. In order to take into account the possibility that because of insertions, deletions, or breakpoints within an exon body, some reads will not align to an exon breakpoint and must be readjusted. JAFFAL utilizes a clustering approach where reads are clustered by genomic position and only one breakpoint is reported per cluster. This one breakpoint is chosen by finding the closest breakpoint within 50bp that aligns to other reads. Finally, breakpoints are ranked as “High Confidence” based on whether they are supported by more than one reads with breakpoints aligning to exon boundaries, or “Low Confidence” in which a fusion is supported by more than one read but the breakpoints do not align to exon boundaries. (Image from Davidson et. al. 2022)
Genion
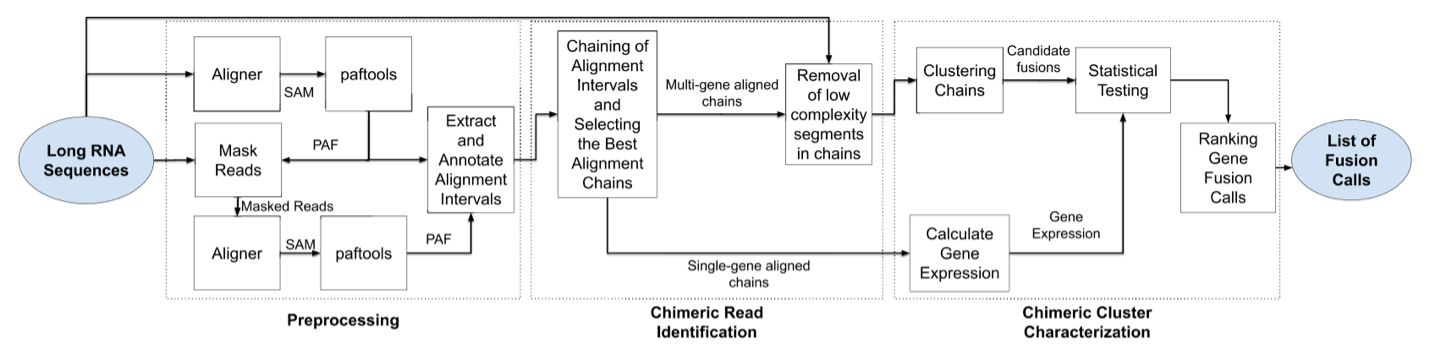
Genion detects fusion transcripts by first using an aligner such as deSALT or minimap2 to map to a reference genome. Interval pairs called segments are extracted from the mappings which represent the locations of the mapped regions on the reads and reference genome. Exon data are matched to these segments. Genion uses a dynamic programming exon chaining algorithm to match reads with one or morse sets of exons that are expressed in the read, called exon chains. Each exon chain is clustered into groups of chimeric reads that are involved with the same two different genes. These clusters are then statistically tested to remove pairings that are likely due to random pairings. A post-processing step is then used to define the biological event that likely generated the cluster. (Image from Karaoglanoglu, et al 2022)
Aerion
Aeron is another piece of software developed for detecting fusions genes from long read transcriptome data which uses a sequence to graph alignment technique. This software appears to still be under construction and we were not able to use this piece of software on are data, so we are not including it in this analysis.
Methods
We obtained the Ensembl (v105) hg38 genome and transcriptome fasta files, as well as gene set GFF files. We first limited transcripts available in the hg38 transcriptome fasta file by excluding any that were not present inside the GFF file and then removed and transcripts that were shorter than 100bp in length. 1,000 transcripts were randomly selected from the remaining transcriptome and were then used to create an abbreviated transcriptome that would be used throughout the experiment as a reference transcriptome.
Fusion transcripts are simulated using an R (v4.0.3) script that picks two transcript, splits them in half and combines them to create a simulated fusion transcript. We simulated 100 fusions genes and spiked them into a reference transcriptome. Both the spiked reference transcriptome and a control without the spiked simulated fusion transcripts were used in this experiment.
ART (Huang, et. al., 2012; v2.5.8) was used to simulate 100bp, and 150bp length reads using its built-in Illumina profile.
Rustyread (rustyread 0.4 Pidgeotto) was used to simulate long reads with built-in error models for pacbio2016 and nanopore2017 . Long read FASTQs were subsampled using seqtk (1.3-r117-dirty) with random seeds for each sampling iteration. Fusion transcript and reference transcriptome FASTQs were then combined according to their coverage levels.
For long reads simulations, each simulation was replicated 10 times across various combinations of parameters. These parameters include per-base coverage levels (3x, 5x, 10x, 30x, 50x, 100x), and for the long read simulations, identity scores were included. These identity scores are composed of a mean value, max value, and a standard deviation. The following values were selected: a poor identity score (75, 90, 8), a mediocre identity score (87, 97, 5), and an excellent quality score (95, 100, 4).
Minimap2 (version 2. 21) uses -ax map-ont for alignment on nanopore simulated reads, and -ax map-pb on PacBio simulated reads.
Samtools (1.9) sort uses the -n option to order by name.
LongGF (0.1.2) was used with the sorted minimap2 alignment data.
JAFFA (2.2) was used running the JAFFAL pipeline on the replicated sets of data.
Genion (1.0.1) was used with the sorted mimimap2 alignment data. The whole genome alignment was performed as described by the software.
STAR (2.7.10a) was used to align short read data with the options:
-outFilterMultimapNmax 50
--peOverlapNbasesMin 10
--alignSplicedMateMapLminOverLmate 0.5
–alignSJstitchMismatchNmax 5 -1 5 5
--chimSegmentMin 10
--chimOutType WithinBAM HardClip
--chimJunctionOverhangMin 10
--chimScoreDropMax 30
--chimScoreJunctionNonGTAG 0
--chimScoreSeparation 1
--chimSegmentReadGapMax 3
--chimMultimapNmax 50
Arriba (2.2.1) was used to detect fusions in the aligned short read data produced by STAR with default parameters.
Results
Comparison of fusion recall across different tools using long reads
We first show a general comparison of long-read fusions detection tools. “Error” corresponds to the average per-base error level of simulated reads. The following graphs show the recall of tools at various levels of coverage (3x, 5x, 10x, 30x, 50x, 100x) at the lowest error level (5%) on simulated Nanopore and PacBio reads (nanopore2020 and pacbio2016 model of the Rustyread simulator)




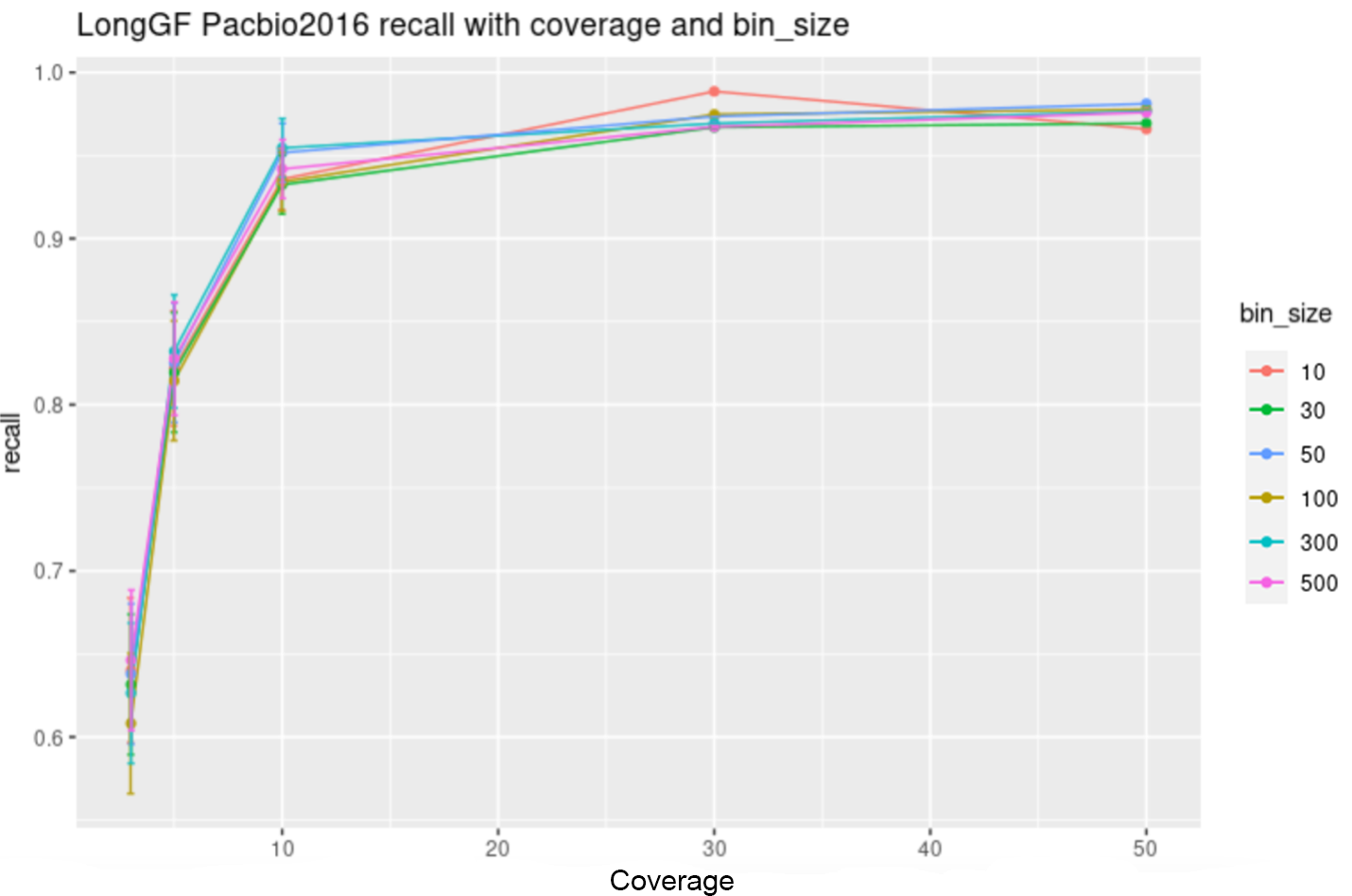
Effect of varying parameters for LongGF
The following graphs shows the area under the precision recall curve of PacBio LongGF data at various coverage levels.
The following figures show LongGF at “excellent” quality (5% error) of pacbio2016 data while varying the values of —min-support-lengths, —bin-size, and —min-map-length arguments:


Effect of varying parameters for Genion
The following graphs shows the area under the precision recall curve of Pacbio2016 Genion data at various coverage levels.
The following figures show LongGF at “Excellent” quality (5% erorr) of pacbio2016 data while varying prefix-length, mid-length, suffix-length, and minimum supplimental reads arguments.




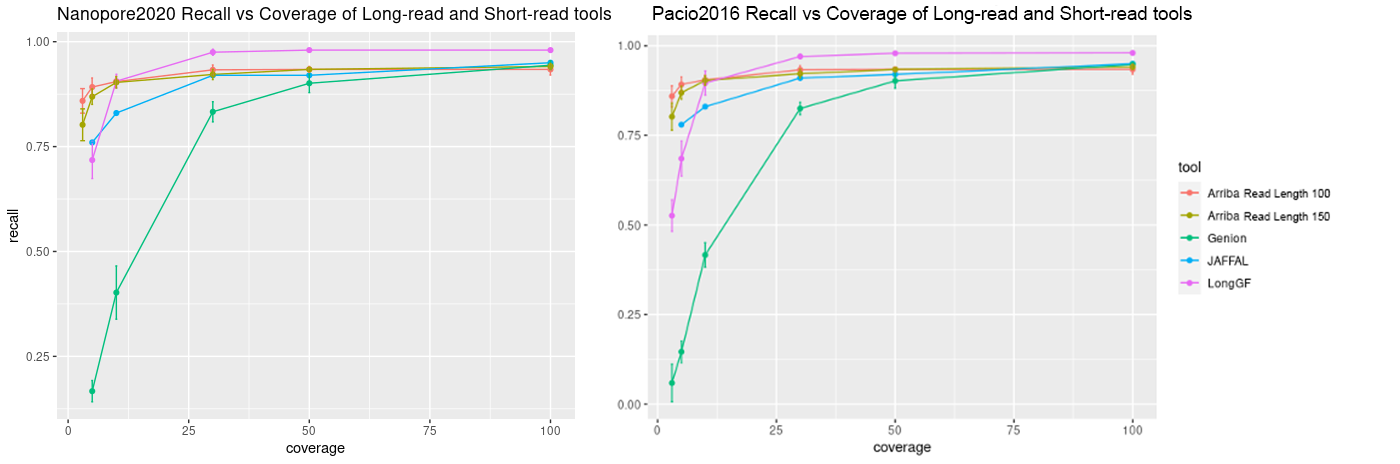
Comparison of long reads vs short reads (detection by Arriba)
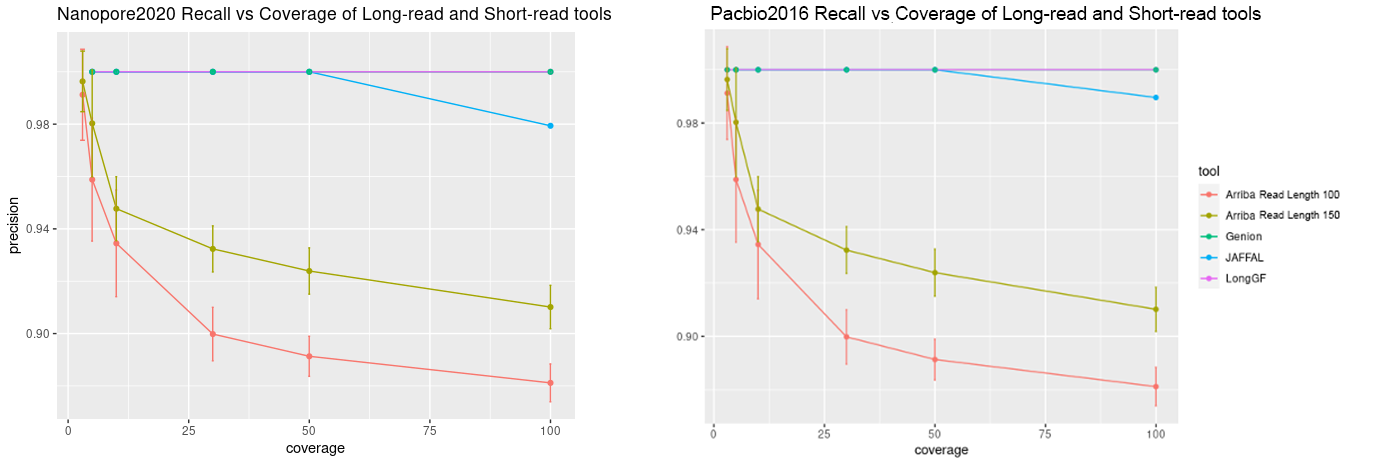
The following graphs show the recall and precision respectively of all three of the long-read fusion detection tools that we used along with the short read fusion detection tool Arriba at various levels of coverage (3x, 5x, 10x, 30x, 50x, 100x) at the mediocre error level (13%) on simulated Nanopore and PacBio reads (nanopore2020 and pacbio2016 model of the Rustyread simulator)
Discussion
Importantly, long read fusion detection tools all seem to have very high specificity on simulated data and can only be compared with regards to recall/sensitivity. LongGF slightly out-performs both Genion and JAFFAL as read coverage increases, though, JAFFAL does outperform LongGF at lower coverage levels. As expected, higher quality reads and higher coverage both increased recall. We see that deviation from standard parameters in LongGF and Genion did not improve these tools’ performance. When comparing short read fusion detection to long read methods, we see that Arriba achieves comparable sensitivity to long read tools at lower coverage levels, however, seems to perform at about at par or worse at higher coverage levels. The precision of Arriba decreases as coverage increases and more false positive are found, whereas long read tools largely do not show a loss of precision.
Our approach of creating fusion transcripts was rather simple and future simulations should be able to simulate different types of fusions events as the ability of these various tools to recapitulate fusions transcripts may vary by type. There are many tools and pipelines beyond those that we tried and it’s possible that these other tools might exceed the performance of the best ones we tried (LongGF and Arriba). Lastly, the degree of generalization from fusions simulated with our particular process and experimental design is unclear and these tools could behave in surprising ways on biological data.
Code Availability
All code used is available in the following github repository: https://github.com/pirl-unc/longread-fusion-transcript-pipeline